Architectures
Evolution of Distributes DBs
Logical multi-processor database design:
- Shared memory (easiest to program, but most expensive)
- Shared disks (easier)
- Shared nothing (hard: MapReduce, etc)
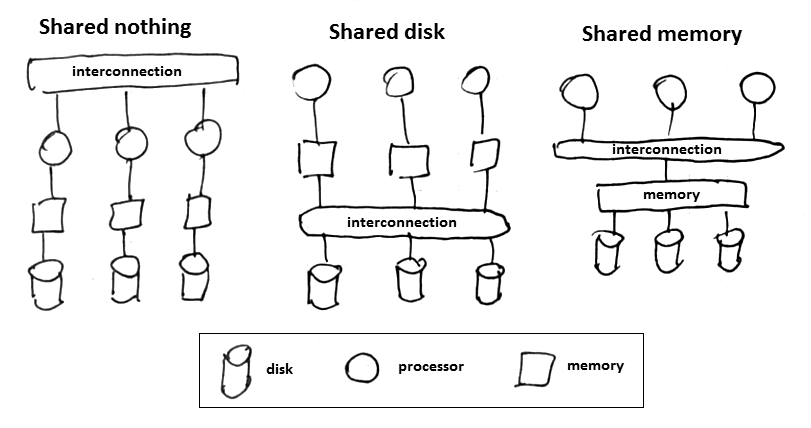
Shared Nothing Architecture
- each processing unit (node, process, thread) is independent and self-sufficient
- it has its own memory and storage
- these is no single point of connection in the system
- allows individual servers to fail (with proper replication)
- data records are distributed by messaging
Assumptions
Assumptions that we make about distributes systems
Data size
- the amounts of data is so big to fit on one node
- and even on a single rack
- $\to$ therefore we need to partition the data across many nodes
Reliability
- the system must be highly available to serve all applications
- nodes may occasionally crash
- but data must be safe
- $\to$ therefore we need to replicate each row to multiple nodes and remain available despite failures
Performance
- for real-time use
- 95/99 percentile is more important than the average latency (we care about longest latency measures)
- want it run on cheap commodity hardware
- $\to$ need to be able to maintain low latency even during recovery operations
Design Principles
Partitioning / Incremental Scalability
- Scale out one node at a time with minimal impact (with techniques like Consistent Hashing)
Symmetry
- no special role node (with extra responsibilities)
- simplifies maintenance
Decentralization
- extension of Symmetry:
- favor peer-to-peer techniques over centralized control
Heterogeneity
- work distribution must be proportional to the capabilities of individual servers
- don’t need to upgrade old servers when adding a newer one
Concurrency Control
Sources
- Introduction to Data Science (coursera)
- Design Patterns for Distributed Non-relational Databases
- Amazon’s Dynamo paper [http://s3.amazonaws.com/AllThingsDistributed/sosp/amazon-dynamo-sosp2007.pdf]