Secondary Storage
This is a part of the Memory Hierarchy
Disks is the most common secondary storage
- The disk is organized into disk ‘‘blocks’’ (or ‘‘pages’’, from the OS point of view) of 4-64 KBs each
- '’Buffers’’ - entire blocks are moved to and from a continuous sections of main memory
Key technique: organize data in a way that
- when something is needed from a block
- it’s likely that other information from that block will also be needed
Main Components
Consists of two main components:
- Disk Assembly
- Head Assembly
Disk Assembly
- has one or more circular ‘‘platters’’ that rotate around a central spindle
- upper and lower surfaces are covered with magnetic materials (that store 1s and 0s)
Hierarchy
- disk is organized into ‘‘tracks’’ - concentric circles on a single platter
- tracks that are at fixed radius from the center (among all the surfaces) form one ‘‘cylinder’’
- tracks are organized into ‘‘sectors’’ - segments that are separated by non-magnetic ‘‘gaps’’
- for each surface there’s one head that reads data, and all the heads form ‘‘the head assembly’’
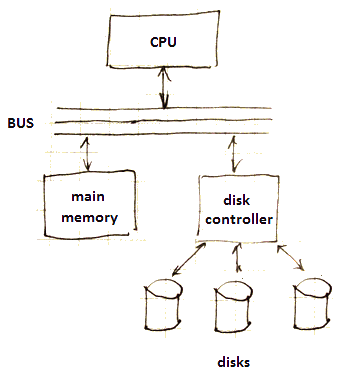
Disk Controller
Disk drives are controlled by a ‘‘disk controller’’ (DC): a small processor that
- controls the head assembly
- selects a needed sector
- transfers bits between sectors and the main memory
- buffers entire track in local memory of the disk controller (in hope it will be needed soon)
It communicates with the main memory via the ‘‘data bus’’
Accessing
Accessing (reading or writing) a block of data requires 3 steps:
- DC positions the head assembly at the cylinder that contains the needed block
- : the time to do it is the ‘‘seek time’’
- DC waits until the first sector of the block appears under the head
- : the ‘‘rotation latency’’
- : typically 0-10 mls, 5 mls on average (1 rotations is 10 mls)
- DC reads/writes sectors under the head while sectors pass under it
- : the ‘‘transfer time’’
- : quite small
the ‘‘latency of disk’’ is a sum of the three:
- seek time + rotation latency + transfer time
- usually ~10-11 mls
- but it doesn’t mean that the system will get all data in 10 mls after sending a request to DC: it may be busy with another processes
Another measure:
- '’throughput’’ - the number of dist accesses per second that the system can accommodate
Techniques to Speed Up Access
Optimizing by Cylinders
place blocks that are accessed together on the same (or adjacent) cylinder
- this way can decrease seek time and possibly the rotation latency
- if we read blocks consequently, then we may neglect all seek times (except for first)
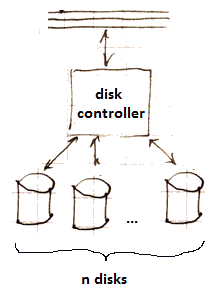
Striping
divide data among several smaller disks (rather than one large one)
- in result, you’ll have more independent head assemblies
- increases the number of block accesses per unit of time
- As long as DC, bus, memory can handle $n$ times the data-transfer rate,
- then $n$ disks will have approximately the performance of 1 disk operating $n$ times faster
- but if the system is overloaded, when requests are delayed (or even cancelled)
'’Striping’’ - this is a technique to speed up access to large DB objects
- (a large DB object is one that spans several disk blocks)
Idea:
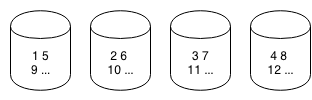
- Suppose we have 4 disks and want to access a relation faster
- then we can “stripe” this relation by dividing it among the 4 disks:
- 1 disk receives blocks 1, 5, 9, …
- 2 disk received blocks 2, 6, 10, …
Mirroring
“Mirror” a disk
- have 2 or more copies of the same information on different disks
- like the previous technique - allows to access several blocks at the same time
- for $n$ disks, rate at which we can read goes up by a factor of $n$
- the speedup can be even greater if DC chooses the disk with its head being closest to the needed block
- but writing doesn’t speed up at all: we need to write data to all $n$ disks
- reliability as a bonus we have a backup if one of the disks fails
Scheduling
it’s possible to use a disk-scheduling algorithm
- to select the order in which several blocks are read/written
- cannot use this approach if we need to have some certain sequence
- but if requests come from independent processes, they can benefit from it (on average)
The Elevator Algorithm: to schedule large numbers of block requests
Idea:
- disk heads go from innermost to outermost cylinder, and then back again
- just as an elevator from bottom to top and back
- as heads pass a cylinder, they stop if there’s a request for block on that cylinder
- they proceed in the same direction until the next required cylinder is met
- if there are no requests ahead, heads reverse the direction
Prefetching
We also can prefetch blocks to the main memory in anticipation they’ll be needed soon
- sometimes it’s possible to predict the order in which blocks will be requested
See also
Sources
- Database Systems: The Complete Book (2nd edition) by H. Garcia-Molina, J. D. Ullman, and J. Widom