Lecture notes for the course “Functional Programming Principles in Scala”
Links:
Functions and Their Evaluation
Definitions
Once values have been defined, they can no longer be changed. The expression of assigning a value to some identifier is called a definition.
def radius = 10
def pi = 3.14159
Definitions can have both parameters and a return type - in this case they should be called functions.
def square(x: Double) = x * x
square(2) => 4
def sumOfSquares(x: Double, y: Double) = square(x) * square(y)
def power(x: Double, y: Int): Double = ...
Function Evaluation Strategies
The Substitution Model is used to evaluate function values.
call-by-value (CBV)
Argument values are evaluated first, then the computed values are passed to the function
- square(2 + 2)
- square(4)
- 4 * 4
- 16
Pros:
- the expression is evaluated only once - from the very beginning
call-by-name (CBN)
Expressions are passed as arguments and are evaluated only when called inside the function body
- square(2 + 2)
- (2 + 2) * (2 + 2)
- 4 * 4
- 16
Pros:
- not evaluated if the parameters are not subsequently used
If CBV terminates (i.e., does not loop and completes), then CBN also terminates, but the converse is not always true.
def loop = loop
def first(x: Int, y: Int) = x
first(1, loop)
With CBN it will execute only once and terminate, while with CBV it will loop and run indefinitely.
By default, Scala uses CBV, but when needed, CBN can be used.
def countOne(x: Int, y: => Int) = 1
x is evaluated as CBV, y as CBN
Definitions
Definitions can also be CBN and CBV
The keyword def creates a CBN definition, val creates a CBV definition
val x = 2
val y = square(2)
val z = square(x)
For val the right-hand side is evaluated immediately and used subsequently (i.e., y refers to 4, not to square(2))
def x = loop // OK
val x = loop // hangs
Conditionals
The conditional expression if else is used to choose between two alternatives
def abs(x: Int) = if (x >= 0) x else -x
Blocks and Lexical Scope
It is considered good programming style to break complex functions into many small ones; however, many functions are only meaningful for a specific implementation of some algorithm and are not intended for external use.
For example, given an algorithm for computing the square root using Newton’s method [(see also link(http://ru.wikipedia.org/wiki/Newton’s_method]))
def sqrt(x: Double): Double =
sqrtIter(1.0, x)
def sqrtIter(guess: Double, x: Double): Double =
if (isGoodEnough(guess, x)) guess
else sqrtIter(improve(guess, x), x)
def isGoodEnough(guess: Double, x: Double) =
abs(guess * guess - x) / x < 0.001
def improve(guess: Double, x: Double) =
(guess + x / guess) / 2
To avoid “namespace pollution”, all auxiliary functions can be placed inside sqrt:
def sqrt(x: Double): Double = {
def sqrtIter(guess: Double, x: Double): Double =
if (isGoodEnough(guess, x)) guess
else sqrtIter(improve(guess, x), x)
def isGoodEnough(guess: Double, x: Double) =
abs(guess * guess - x) / x < 0.001
def improve(guess: Double, x: Double) =
(guess + x / guess) / 2
sqrtIter(1.0, x)
}
In this case, the curly braces define a code block, which is also an expression (and therefore returns some value). This is called the lexical scope of the block.
Scoping rules:
- All definitions inside a code block are not visible outside it (local scope)
- Definitions outside the block are visible inside the block (parent scope)
- Definitions inside the block (in the local scope) shadow definitions outside the block (i.e., in the parent scope)
val x = 0
val res = {
val x = f(3)
x * x
} + x
In this example, inside the block the variable x is shadowed by the value returned by function f, then the block returns a value, which is then added to the original x.
Higher-Order Functions
Functions in Scala are first-class objects. That is, a function can be passed as a parameter or returned as a value. Functions that do this are called higher-order functions.
def sum(f: Int => Int, a: Int, b: Int): Int =
if (a > b) 0
else f(a) + sum(f, a + 1, b)
def sumInts(a: Int, b: Int) = sum(id, a, b)
def sumCubes(a: Int, b: Int) = sum(cube, a, b)
def sumFactorials(a: Int, b: Int) = sum(fact, a, b)
def id(x: Int): Int = x
def cube(x: Int): Int = x * x * x
def fact(x: Int): Int = if (x == 0) 1 else fact(x - 1)
The type A => B describes a function that takes an argument of type A and returns a result of type B. Int => Int takes an Int and returns an Int.
A function without a name is called an anonymous function
(x: Int) => x * x
(x: Int, y: Int) => x + y
The left part of the function lists the parameters, and the right part is called the body of the anonymous function.
Function parameters can be omitted if the compiler can infer them.
def sumInts(a: Int, b: Int) = sum(x => x, a, b)
def sumCubes(a: Int, b: Int) = sum(x => x * x * x, a, b)
Currying
Consider the example
def sumInts(a: Int, b: Int) = sum(x => x, a, b)
The arguments a and b are simply passed through without changes, so it is possible to make this function even shorter
def sum(f: Int => Int): (Int, Int) = {
def sumF(a: Int, b: Int): Int =
if (a > b) 0
else f(a) + sum(a + 1, b)
sumF
}
sum is a function that returns another function which “remembers” f and knows how to compute the value. Then we can write
def sumInts = sum(x => x)
def sumCubes = sum(x => x * x * x)
def sumFactorials = sum(fact)
That is,
sumCubes(1, 10) == (sum(cube))(1, 10)
sum(cube) returns a function that is immediately applied to arguments 1 and 10.
In Scala, there is special syntax for such functions:
def sum(f: Int => Int)(a: Int, b: Int): Int =
if (a > b) 0 else f(a) + sum(f)(a + 1, b)
This is called currying.
Example: Finding a Fixed Point
Finding a Fixed Point [link(http://ru.wikipedia.org/wiki/Fixed_point])
$x$ is called a fixed point of function $f$ if $f(x) = x$
For some functions, we can find a fixed point by applying the function to some initial value, then applying the same function to the result, then again, and so on.
$x, f(x), f(f(x)), f(f(f(x))), …$
until two consecutive members of such a sequence differ insignificantly.
val tolerance = 0.0001
def isCloseEnough(x: Double, y: Double) =
abs((x - y) / x) / x < tolerace
def fixedPoint(f: Double => Double)(firstGuess: Double) = {
def iterate(guess: Double): Double = {
val next = f(guess)
if (isCloseEnough(guess, next)) next
else iterate(next)
}
iterate(firstGuess)
}
The function $f = \sqrt{x}$ returns a number y such that $y \cdot y = x$, or, dividing by $y$, $y = \frac{x}{y}$
Therefore, $f = \sqrt{x}$ is a fixed point of the function $y = \frac{x}{y}$
def sqrt(x: Double) = fixedPoint(y => x / y)(1.0)
However, this function will not converge but will oscillate: 1.0, 2.0, 1.0, 2.0, …
This can be avoided by averaging the two most recent values:
def sqrt(x: Double) = fixedPoint(y => (x + x / y) / 2)(1.0)
This technique for stabilizing an oscillating function is called average damp, and it is general enough to extract this logic into a separate function:
def averageDamp(f: Double => Double)(x: Double) = (x + f(x)) / 2
The final result is
def sqrt(x: Double) = fixedPoint(averageDamp(x => x / y))(1.0)
Example: Sets
A type alias is a new identifier for an already existing type.
For sets, we can define the following alias:
type Set = Int => Boolean
That is, a set can be represented as a function that takes a number and returns true if the number is in the set, and false otherwise.
For example, to represent the set of all negative numbers, one can write:
(x: Int) => x < 0
Accordingly, the contains function takes the following form:
def contains(s: Set, elem: Int): Boolean = s(elem)
Functions and Data Structures
How to use functions to create and encapsulate data structures.
Example: Rational Numbers
We want to design a package that allows performing arithmetic operations on rational numbers.
A rational number can be represented as two numbers $x$ and $y$: numerator $x$ and denominator $y$
class Rational(x: Int, y: Int) {
def numer = x
def denom = y
}
In this definition, Rational adds to the code:
- a new type -
Rational - a constructor that can be used to create elements of type
Rational
new Rantional(1, 2) // constructor
The definitions numer and denum are called class members. Class members are accessed using the infix operator . (dot):
x.numer
x.denum
The following operations can be performed on rational numbers:
- $\cfrac{n_1}{d_1} + \cfrac{n_2}{d_2} = \cfrac{n_1 d_2 + n_2 d_1}{d_1 d_2}$
- $\cfrac{n_1}{d_1} - \cfrac{n_2}{d_2} = \cfrac{n_1 d_2 - n_2 d_1}{d_1 d_2}$
- $\cfrac{n_1}{d_1} \cdot \cfrac{n_2}{d_2} = \cfrac{n_1 n_2}{d_1 d_2}$
- $\cfrac{n_1}{d_1} / \cfrac{n_2}{d_2} = \cfrac{n_1 d_2}{d_1 n_2}$
- $\cfrac{n_1}{d_1} = \cfrac{n_2}{d_2} \iff n_1 d_2 = d_1 n_2$
For each of these operations, we can create a function
def addRational(r: Rational, s: Rational): Rational =
new Rational(r.numer * s.denom + s.numer * r.denom, r.denom * s.denom)
//...
def makeString(r: Rational) =
r.numer + "/" + r.denom
But these functions can be placed inside the Rational abstraction - such functions are then called methods.
class Rational(x: Int, y: Int) {
def numer = x
def denom = y
def add(r: Rational) =
new Rational(numer * r.denom + r.numer * denom, denom * r.denom)
//...
def override toString = numer + "/" + denom
}
(The keyword override indicates that the method toString already exists)
val x = new Rational(1, 3)
val y = new Rational(5, 7)
val z = new Rational(9, 11)
x.add(y).mul(z)
One can notice that in some cases a fraction can be simplified (reduced)
class Rational(x: Int, y: Int) {
private def gcd(a: Int, b: Int): Int =
if (b == 0) a else gcd(b, a % b)
private val g = gcd(x, y)
def numer = x / g
def denom = y / g
//...
}
The keyword private is used when class members should be visible only within the class definition and not visible from outside (i.e., they can only be accessed within the Rational class).
Constructors
A class definition implicitly declares its constructor. Such a constructor is called the primary constructor.
The primary constructor:
- takes the class parameters
- executes all expressions in the class body
We can also declare auxiliary constructors - they are declared using a method named this:
class Rational(x: Int, y: Int) {
//...
def this(x: Int) = this(x, 1)
}
new Rational(2) // -> 2/1
Identifiers and Operators
In Scala, it is possible to write
r add s
r mul s
instead of
r.add(s)
r.mul(s)
And an operator can be used as an identifier.
Identifier naming rules:
- an identifier can start with a letter and consist of letters and digits
- an identifier can start with an operator symbol and consist of other operator symbols
_(underscore) is considered a letter- alphanumeric identifiers can end with an underscore followed by operator symbols
For example, x1, *, +?%&, vector_++, counter_=.
Thus, we can define the following methods:
class Rational(x: Int, y: Int) {
def numer = x
def denom = y
def +(r: Rational) = //...
def -(r: Rational) = //...
def *(r: Rational) = //...
//...
}
val x = new Rational ...
val y = new Rational ...
x * x + y * y
// same as
(x * x) + (y * y)
Operator precedence is determined by the first character of their name. Precedence:
- letters
|^&< >= |:+ -* / %- all other special characters
Example:
a + b ^? c ^? d less a ==> b | c |((a + b) ^? (c ^? d)) less ((a ==> b) | c) |
Creating Class Hierarchies
An abstract class is a class that can contain methods that are not yet implemented.
Consider an example - a set of integers.
abstract class IntSet {
def incl(x: Int): IntSet
def contains(x: Int): Boolean
}
The new operator cannot be applied to abstract classes - i.e., an object of such a class cannot be created.
Extension is a relationship between classes in which one class is the base or superclass for the second class - the subclass. The base class provides its methods for the subclass to use, which in turn can add new methods (i.e., extend the base class).
If a class extends an abstract class, it must implement its abstract methods.
class Empty extends IntSet {
def contains(x: Int): Boolean = false
def incl(x: Int): IntSet = new NonEmpty(x, new Empty, new Empty)
}
class NonEmpty(elem: Int, left: IntSet, right: IntSet) extends IntSet {
def contains(x: Int): Boolean =
if (x < elem) left contains x
else if (x > else) right contains x
else true
def incl(x: Int): IntSet =
if (x < elem)
new NonEmpty(elem, left incl x, right)
else if (x > elem)
new NonEmpty(elem, left, right incl x)
else this
}
Both classes Empty and NonEmpty extend IntSet and both correspond to the same type IntSet - an object of type Empty or NonEmpty can be used wherever an object of type IntSet is required.
IntSet is the base class for Empty and NonEmpty, while Empty and NonEmpty are subclasses of IntSet.
Classes Empty and NonEmpty implement the abstract definitions incl and contains from IntSet. It is also possible to override existing non-abstract definitions of the parent class in a subclass using the keyword override.
abstract class Base {
def foo = 1
def bar: Int
}
class Sub extends Base {
override def foo = 2
def bar = 3
}
Value parameters
To define class fields, the keyword val can be used in the constructor
class Cons(val head: Int, val tail: IntList) extends IntList {
// ...
}
This notation is equivalent to the following:
class Cons(_head: Int, _tail: IntList) extends IntList {
val head = _head
val tail = _tail
// ...
}
Singletons
In this example, only one EmptySet is needed, and there is no need to create a new object each time, so we can define a singleton object. Only one singleton object exists and no more can be created.
object Empty extends IntSet {
def contains(x: Int): Boolean = false
def incl(x: Int): IntSet = new NonEmpty(x, new Empty, new Empty)
}
Traits
As in Java, a class in Scala can have only one superclass. To enable code reuse from multiple superclasses, traits are used.
Declaring a trait is similar to declaring an abstract class, but a subclass can use multiple traits with the keyword with
trait Planar {
def height
def width
def surface = heigh * width
}
class Square extends Shape with Planar with Movable {
// ...
}
Traits are similar to interfaces in Java, but
- they can contain fields and
- concrete methods
Code Organization
Application Entry Point
The entry point of an application is the place where program execution begins. In Scala, this is the main method:
object Hello {
def main(args: Array[String]) = println("hw| ") |} |
To run the application, write
scala Hello
Packages
Packages are used to organize classes and objects
package progfun.exmaple
object Hello {
def main(args: Array[String]) = println("hw| ") |} |
The fully-qualified name of a class consists of the package name and the class name, for example, progfun.example.Hello
To start the application, specify the fully-qualified class name:
scala progfun.example.Hello
Imports
We can refer to a class/object by its fully-qualified name
val r = new week3.Rational(1, 2)
But this is inconvenient, so we can import from another package and then use only the short class name
import week3.Rational
val r = new Rational(1, 2)
We can also specify which classes to import from a package, or import everything
import week3.{Rational, Hello}
import week3._ // wildcard import
Imports can be made not only from packages but also from objects
Some classes and objects are imported automatically. These include the contents of the following packages:
- java.lang
- scala
- scala.predef
Types
Type Hierarchies in Scala
- The base type for all types in Scala is the type
Any, which contains basic methods like==,| =, etc. - For all classes, the base class is
AnyRef(which is a synonym forjava.lang.Object) - For primitives, the base type is
AnyVal
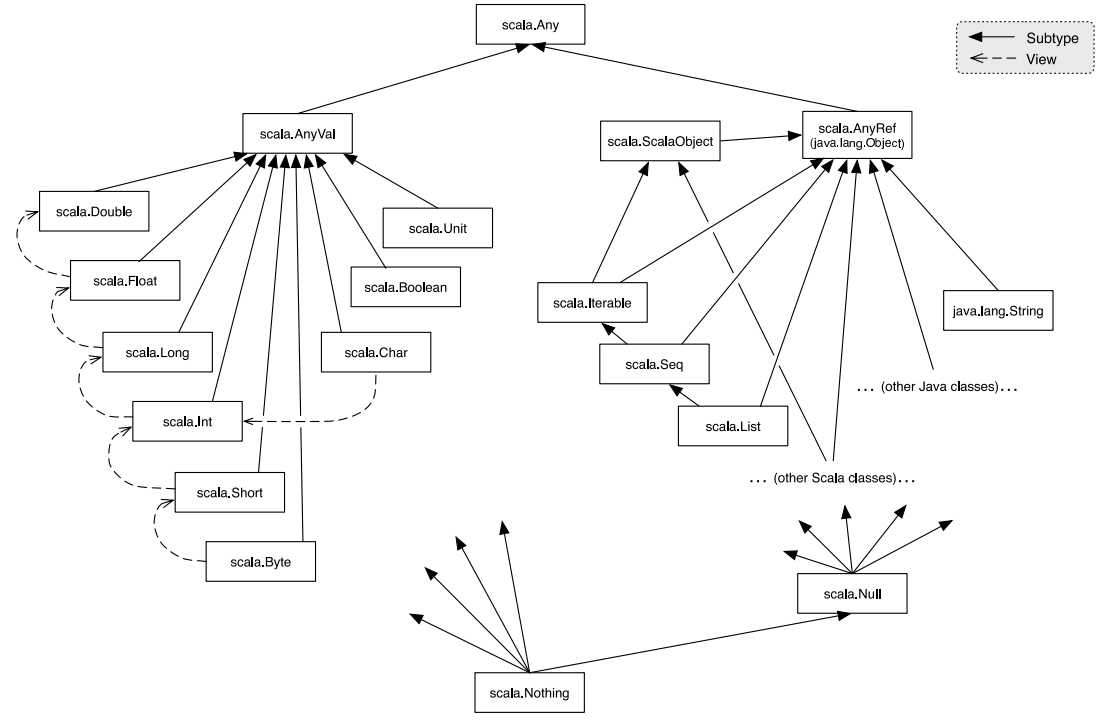
- The type
Nothingis at the bottom of the hierarchy and is a subtype of all types. - Scala also has the type
Null, which is the type of the valuenull.Nullis a subclass of all subclasses ofAnyRef
val x = null // x: Null
val y: String = null // y: String
val z: Int = null // error: type mismatch (not a subclass of AnyRef)
Parameterized Types
Consider a Cons-list - an immutable linked list built from the following elements:
Cons- a cell containing an element and a reference to the next part of the listNil- an empty list
trait IntList ...
class Cons(val head: Int, val tail: IntList) extends IntList ...
class Nil extends IntList ...
However, this definition is too narrow: such a list can only be used with the Int type. But we can generalize the definition of our list using type parameters
trait List[T] ...
class Cons(val head: T, val tail: List[T]) extends List[T] ...
class Nil extends List[T] ...
Functions, like classes, can also have such parameters
def signleton[T](elem: T) = new Cons[T](elem, new Nil[T])
signleton[Int](1)
signleton[Boolean](true)
However, Scala can infer the needed type, so the parameter can be omitted
signleton(1)
signleton(true)
Functions as Objects
Functions in Scala are objects. The function type A => B is actually a shorthand for scala.Function[A, B], which is defined as
package scala
trait Function1[A, B] {
def apply(x: A): B
}
That is, functions are objects that have an apply method
An anonymous function declaration can be written using a class as follows:
// anonymous
(x: Int) => x * x
{
class AnonFunc extends Function1[Int, Int] {
def apply(x: Int) = x * x
}
new AnonFunc
}
Or, using the syntax for anonymous class declarations
new Function1[Int, Int] {
def apply(x: Int) = x * x
}
For example,
val f = (x: Int) => x * x
f(7)
Becomes
val f = new Function1[Int, Int] {
def apply(x: Int) = x * x
}
f.apply(7)
Methods are not functions, but they can also be used as functions - and they are automatically converted to functions as follows
(x: Int) => f(x)
Subtypes and Generics
Type Bounds
Consider the method assertAllPos, which
- Takes an
IntSet - Returns the received
IntSetif all its elements are positive - Throws an exception otherwise
What type is best suited for the parameter of this method?
def assertAllPos(s: IntSet): IntSet
But
assertAllPos(Empty)should returnEmptyassertAllPos(NonEmpty)should returnNonEmpty
This can be done using an upper bound of the parameterized type
def assertAllPos[S <: IntSet](r: S): S = ...
This definition means that the parameter S can only take types that correspond to IntSet (i.e., are either objects of this class or any of its subclasses).
In general, the following notation is used:
S <: T- upper bound,Sis a subtype ofTS >: T- lower bound,Sis a supertype ofT, orTis a subtype ofS
It is also possible to bound a type both from above and below simultaneously.
For example, [S >: NonEmpty <: IntSet] bounds S between IntSet and NonEmpty.
Covariance
If NonEmpty <: IntSet, does List[NonEmpty] <: List[IntSet] hold?
Such a relationship is called covariance, and types that support this are called covariant.
However, covariance does not always make sense. For example, arrays in Java are covariant, but this causes a number of problems. Consider the following code:
NonEmpty[] a = new NonEmpty[] { new NonEmpty(...) }
IntSet[] b = a
b[0] = Empty
NonEmpty s = a[0] // ArrayStoreException
Liskov Substitution Principle
If A <: B, then everything that can be done with a value of type B must also work for values of type A.
As seen from the example, covariance does not always bring benefits. Some types should be covariant and some should not.
However, if certain conditions are met, immutable types can be covariant. For example, List can be covariant.
Let C[T] be a parameterized type, and A and B be types such that A <: B. There are three possible relationships between C[A] and C[B]:
- C[A] <: C[B], i.e., type C[A] is a subtype of C[B]. This relationship is called covariant
- C[A] >: C[B], i.e., type C[B] is a subtype of C[A]. This relationship is called contravariant
- neither C[A] nor C[B] is a subtype of the other. This relationship is called non-variant
In Scala, the following notation is used:
class C[+A] {...} // covariant
class C[-A] {...} // contravariant
class C[A] {...} // non-variant
Types for Functions
- If
A2 <: A1andB1 <: B2, - then
A1 => B1 <: A2 => B2
That is, functions are contravariant in their argument types and covariant in their result types.
Thus, we have the following definition for functions:
package scala
trait Function1[-T, +U] {
def apply(x: T): U
}
In the array example, the problematic operation was the array update operation. If we represent the array as a class, we get
class Array[+T] {
def update(x: T)
}
In this class, the problem is caused by
- The covariant type parameter
T - Which is used for a parameter in the
updatemethod
The Scala compiler checks that there are no such problematic combinations in the code.
In summary,
- Covariant types can only be used in method results
- Contravariant types only in method parameters
- Invariant types can be used anywhere
We can make List covariant
trait List[+T] {...}
object EmptyList extends List[Nothing] {...}
We would like to have a singleton object for the empty list, since for an empty list it does not matter what is inside - it is always empty.
Consider the method prepend which adds a new element and returns a new list
trait List[+T] {
def prepend(elem: T): List[T] = new Cons(elem, this)
}
This definition will not pass the variance check, as a covariant type is used in a method parameter.
Moreover, this violates the Liskov Substitution Principle. Suppose we have a list xs of type List[IntSet]
xs.prepend(Empty)
We add an empty set to such a list. But if we consider a list ys of type List[NonEmpty], we get an error when trying to prepend the empty set:
ys.prepend(Empty) // type mismatch, required: NonEmpty, found: Empty
That is, List[NonEmpty] cannot be a subtype of List[IntSet]
How can this be fixed?
We can add a lower bound for the type parameter of the prepend method
def prepend[U >: T](elem: U): List[U] = new Cons(elem, this)
This passes the variance check because
- covariant type parameters can be used as lower bounds for method types
- similarly, contravariant type parameters can be used as upper bounds
And finally, consider the following function
def f(xs: List[NonEmpty], x: Empty) = xs prepend x
The return type of this function will be List[IntSet]
Pattern Matching
As an example, consider a small interpreter for arithmetic operations. All expressions can be represented as a class hierarchy, with a base trait Expr and subclasses Number and Sum (we limit ourselves to numbers and the addition operation).
We can use the OOP approach
trait Expr {
def eval: Int
}
class Number(n: Int) extends Expr {
def eval: Int = n
}
class Sum(e1: Expr, e2: Expr) extends Expr {
def eval: Int = e1.eval + e2.eval
}
Limitation of this approach:
- What if we want to simplify expressions using a set of rules?
- For example $a \cdot b + a \cdot c = a \cdot (b + c)$.
- The problem is that this simplification is not local, i.e., it cannot be encapsulated in a method of only one object
- Changes must be made to all classes when adding a new method
Case Classes
Consider the following definition:
trait Expr
case class Number(n: Int) extends Expr
case classs Sum(e1: Expr, e2: Expr) extends Expr
object Number {
def apply(n: Int) = new Number(n)
}
object Sum {
def apply(e1: Expr, e2: Expr) = new Sum(e1, e2)
}
The objects Number and Sum are needed so that one can write Number(1) instead of new Number(1) (such objects are called companion objects).
Pattern matching is a generalization of the switch construct from Java for class hierarchies. Classes marked with the keyword case can be used in pattern matching constructs.
def eval(e: Expr): Int = e match {
case Number => n
case Sum(e1, e2) => eval(e1) + eval(e2)
}
Declaration rules:
- the keyword
matchis used, and - a sequence of the form
pattern => expressionfor each case - for each case, the expression is matched against the pattern
- if none of the patterns can be matched with the given value, a
MatchErroris thrown
Pattern Forms
Patterns can be composed of
- constructors (e.g.,
Number,Sum) - variables (
n,e1,e2) - wildcard patterns (
_), which match any value - constants, e.g.,
1,true, etc.
For example, the constructor Sum(x, y) matches an object of type Sum, and the variables x and y receive the values of the left and right operands.
Also, tuples (pairs, etc.) and lists can be used as patterns (see below for details)
case (c, count)matches a pair;creceives the first value,countthe secondx :: xsmatches a list;xreceives the head of the list,xsthe tail
Examples:
def singleton(trees: List[CodeTree]): Boolean = trees match {
case x :: Nil => true
case _ => false
}
def nextBranch(tree: Fork, bit: Bit): CodeTree = bit match {
case 0 => tree.left
case 1 => tree.right
case _ => throw new IllegalArgumentException("unexpected value for bit: " + bit)
}
def decode1(currentBranch: CodeTree, bits: List[Bit]): List[Char] = (currentBranch, bits) match {
case (Leaf(char, _), Nil) => List(char)
case (fork: Fork, head :: tail) => decode1(nextBranch(fork, head), tail)
case (Leaf(char, _), head :: tail) => char :: decode1(tree, bits)
case (_: Fork, Nil) => throw new IllegalStateException("the sequence of bits ended abruptly")
case _ => throw new IllegalStateException()
}
A guard condition can also be used for each pattern, under which the expression will be executed only if the condition is satisfied. For example,
def positiveSingleton(xs: List[Int]): Boolean = xs match {
case x :: Nil if x > 0 => true
case _ => false
}
Lists
A list consisting of elements $x_1, …, x_n$ is written in Scala as follows:
List(x1, ..., xn)
Key characteristics of lists:
- Lists are immutable
- Lists are defined recursively (a list consists of an element called the head and a list called the tail).
- Lists are homogeneous - i.e., they can consist only of elements of the same type
In Scala, lists are constructed using
- The empty list
Nil - The
::operator (also known asCons) for prepending a new element to the list
Operations on Lists
x :: xs
Prepends element $x$ to list $xs$
fruit = "apples" :: ("pears" :: Nil)
nums = 1 :: (2 :: (3 :: Nil))
empty = Nil
The :: operation is right-associative, so parentheses can be omitted
fruit = "apples" :: "pears" :: Nil
nums = 1 :: 2 :: 3 :: Nil
The :: operation is a method, so the following two notations are equivalent
nums = 1 :: 2 :: 3 :: Nil
nums = Nil.::(3).::(2).::(1)
Lists can be used in pattern matching
NilorList()matches the empty listx :: xsmatches the headxand tailxsof a listList(x1, x2, x3)matches a list consisting of three elements
Example: insertion sort
def sort(xs: List[Int]): List[Int] = xs match {
case List() => List(x)
case y :: ys => if (x <= y) x :: xs else y :: insert(x, ys)
}
In addition, lists have the following methods defined:
xs.head- returns the first element of the listxs.tail- returns all elements except the firstxs.isEmptyreturnstrueif the list is empty,falseotherwise
Also:
xs.length- length of the listxs.last- last elementxs.init- all elements except the lastxs take n- returns the firstnelements of the list (orxsitself if it contains fewer thannelements)xs drop n- returns the list obtained by dropping the firstnelementsxs(i)orxs.apply(i)- returns thei-th element of the listxs ++ ys- concatenates two listsxs.reverse- reverses the listxs.updated(n, x)- returns the list obtained from the original where the element at positionnisxxs.indexOf(x)- index of elementxin the listxs.contains(x)-trueif the element is contained in the list
Higher-Order Functions for Lists
When processing lists, the following tasks are most common:
- Transforming each element of the list
- Filtering elements
- Combining all values of the list into one
Map
Applies a function to each element
class List[T] {
def map[U](f: T => U): List[U] = this match {
case Nil => this
case x :: xs => f(x) :: xs.map(f)
}
}
val scaled = xs.map(x => x * factor)
val squares = xs.map(x => x * x)
Filter
Filters elements satisfying some condition
class List[T] {
def filter(p: T => Boolean): List[T] = this match {
case Nil => this
case x :: xs => if (p(x))
x :: xs.filter(p)
else
xs.filter(p)
}
}
Variations of the filter function:
xs filterNot- same asxs filter (x => | p(x))xs partition p- same as(xs filter p, xs filterNot p), but done in one passxs takeWhile p- returns the prefix of the list satisfying the predicatexs dropWhile p- the remainder of the list after removing elements satisfying the predicatexs span p- same as(xs takeWhile p, xs dropWhile p), but done in one pass
Example:
The pack function that performs the following transformation:
"a","a","a","b","c","c","c","a" => List("a","a","a"), List("b"), List("c","c","c"), List("a")
def pack[T](xs: List[T]): List[List[T]] = xs match {
case Nil => Nil
case x :: xs1 => {
(l, r) = xs.span(el => x == el)
List(l) :: pack(r)
}
}
Reduce
Reduces the list.
A commonly used operation, for example:
- sum: $0 + x_1 + x_2 + … + x_n$
- product: $1 \cdot x_1 \cdot x_2 \cdot … \cdot x_n$
reduceLeft
def sum(xs: List[Int]) =
(0 :: xs) reduceLeft((x, y) => x + y)
def product(xs: List[Int]) =
(1 :: xs) reduceLeft((x, y) => x * y)
Instead of writing (x, y) => x + y, one can write (_ * _)
Each _ represents a parameter, so the functions above can be rewritten as follows:
def sum(xs: List[Int]) =
(0 :: xs) reduceLeft(_ + _)
def product(xs: List[Int]) =
(1 :: xs) reduceLeft(_ * _)
reduceLeft is defined using the more general function foldLeft. foldLeft works similarly to reduceLeft, but also takes an accumulator as an argument - a value that will be returned when the function is applied to an empty list.
Thus, sum and product can be written as
def sum(xs: List[Int]) =
(xs foldLeft 0) reduceLeft(_ + _)
def product(xs: List[Int]) =
(xs foldRight 1) reduceLeft(_ * _)
These two functions can be implemented as follows:
class List[T] {
def reduceLeft(op: (T, T) => T): T = this match {
case Nil => throw ...
case x :: xs => (xs foldLeft x)(op)
}
def foldLeft[U](z: U)(op: (U, T) => U): U = this match {
case Nil => z
case x :: xs => (xs foldLeft op(z, x))(op)
}
}
In addition to foldLeft and reduceLeft, the functions foldRight and reduceRight are also defined
class List[T] {
def reduceRight(op: (T, T) => T): T = this match {
case Nil => throw ...
case x :: Nil => x
case x :: xs => op(x, xs.reduceRight(op))
}
def foldRight[U](z: U)(op: (T, U) => U): U = this match {
case Nil => z
case x :: xs => op(x, (xs foldRight z)(op))
}
}
For operations that are associative and commutative, foldLeft and foldRight are equivalent; however, one of them may be more efficient.
Collections
Vector
Lists are linear, i.e., access to the first element of a list is very fast, but to access an element in the middle or at the end, all preceding elements must be traversed.
However, Scala has alternative implementations of sequences (the Seq interface), for example, Vector, which provides more efficient element access operations.
val nums = Vector(1, 2, 3)
val people = Vector("Bob", "James", "Peter")
Vectors support the same operations as lists, except for the :: operation. Instead, the following operations are defined:
x +: xs- creates a new vector with element x at the beginningxs :+ s- creates a new vector with element x at the end
Range
Objects of type Range represent evenly spaced integers
They are created using three operations:
to(inclusive)until(exclusive)by(step)
val r: Range = 1 until 5 // 1, 2, 3, 4
val s: Range = 1 to 5 // 1, 2, 3, 4, 5
1 to 10 by 3 // 1, 4, 7, 10
6 to 1 by -2 // 6, 4, 2
Seq
Seq is the common base class for Vector, List, and Range:
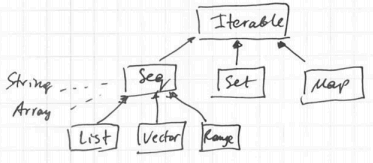
Strings (type String) and arrays (type Array) support the same operations as Seq, and are implicitly converted to the Seq type when needed (but they cannot be subclasses of Seq since they come from Java)
For Seq objects, the following operations are also defined:
xs exists p-trueif at least one element satisfiespxs forall p-trueif all elements satisfypxs zip ys- returns a sequence of pairs composed of corresponding elements from xs and ysxs unzip ys- the inverse operation ofzipxs flatMap f- for cases when f returns a collection, flatMap “glues” the overall result into a single collection
And also:
xs.sumxs.productxs.maxxs.min
Examples
All combinations for $x \in [1..M]$ and $y \in [1..N]$
(1 to M) flatMap (x => (1 to N) map (y => (x, y)))
Dot product of two vectors:
def scalarProduct(xs: Vector[Double], ys: Vector[Double]): Double =
(xs zip ys).map(xy => xy._1 * xy._2).sum
Which, using a pattern matching function value, can be written as:
(xs zip ys).map { case (x, y) = x * y }.sum
Primality test
def isPrime(n: Int): Boolean =
(2 until n) forall (d => u % d | = 0) |
``` |
### For-Expressions
From a list of people, we want to output the names of those older than 20:
persons filter (p => p.age > 20) map (p => p.name)
We can do the same using the <code>for</code> construct:
```s
for (p <- persons if p.age < 20) yield p.name
Syntax:
for (s) yield e
Where
sis a sequence of generators and filters-
eis an expression that will be returned for each object - a generator has the form
p <- epis a patterneis an expression
- a filter has the form
if ffis an expression returningBoolean
The sequence must start with a generator. If there are multiple generators, the last generator changes faster than the first.
Instead of parentheses, {} can be used, and then generators can be written on multiple lines
for {
i <- 1 until n
j <- i until i
if isPrime(i + j)
} yield (i, j)
Thus, the dot product can be written as:
(for ((x, y) <- xs zip ys) yield y * x).sum
Set
A data type representing a set - a collection in which elements do not repeat.
val fruit = Set("apple", "banana", "pear")
val s = (1 to 6).toSet
Most operations for sequences are also available for sets:
s map (_ + 2)
fruit filter (_.startsWith("app"))
Example: 8 Queens
The problem link: how to place $N$ queens so that none can capture another. That is, the queens must be placed so that none of them is on the same row, column, or diagonal.
Algorithm:
- assume we already have a solution for the first $k-1$ queens on a board of size $n$
- each solution is a list of length $k-1$ containing the column numbers where the queens stand (from 0 to $n-1$)
- to place a queen on the $k$-th column, we generate all possible positions and filter out those where conditions are violated
def queens(n: Int) = {
def placeQueens(k: Int): Set[List[Int]] = {
if (k == 0)
Set(List())
else
for {
queens <- placeQueens(k - 1)
col <- 0 until n
if isSafe(col, queens)
} yield col :: queens
}
placeQueens(n)
}
def isSafe(col: Int, queens: List[Int]): Boolean = ...
Map (Data Structure)
Map[Key, Value] is an associative container for key-value pairs.
val roman = Map("I" -> 1, "V" -> 5, "X" -> 10)
val capitals = Map("US" -> "Washington", "Switzerland" -> "Bern")
The class Map[Key, Value] extends Iterable[(Key, Value)], so anything can be done with objects of this type:
val countries = capitals map { case (x, y) => (y, x) }
For extraction, simply apply the map to a key:
capital("Andorra")
However, if the key does not exist, java.utils.NoSuchElement will be thrown.
Alternatively, the get method can be used, which always returns values of type Option
Option
Objects of type Option come in two varieties: one contains some value, and the other is always empty.
trait Option[+A]
case class Some[+A](value: A) extends Option[A]
object None extends Option[Nothing]
The get method returns
Noneif the map does not contain the keySome(x)if it does
def showCapital(country: String) = capital.get(country) match {
case Some(capital) => capital
case None => "missing data"
}
Group By
A collection can be turned into a Map of collections using the groupBy operation:
fruit groupBy(_.head)
Returns
Map(
p -> List(pear, pineapple),
a -> List(apple),
o -> List(orange)
)
A map with a default value can also be created, which will be used when a key is not found
val cap1 = capitals withDefaultValue "unknown"
cap1("Andorra") // "unknown"
Variable-Length Parameters
Suppose we have a class Polynom:
Polynom(Map(1 -> 2.0, 3 -> 4.0, 5 -> 6.2))
Can we avoid passing Map? We can use a repeated parameter
def Polynom(bindings: (Int, Double)*) =
new Polynom(bindings.toMap withDefaultValue 0)
Now this can be used without Map:
Polynom(1 -> 2.0, 3 -> 4.0, 5 -> 6.2)
Lazy Evaluation
Stream
link. Given the task: compute the second prime number in the sequence between 1000 and 10000.
((1000 to 10000) filter isPrime)(1)
But this code finds all prime numbers in the given range while using only 2.
We could lower the upper bound of the range, but risk that a second prime number might not exist in the interval.
However, we can avoid computing the tail of the sequence until it is explicitly needed.
The Stream data structure is built on this principle and is internally very similar to a list. The only difference: the tail of a stream is computed only when needed.
Stream.cons(1, Stream.cons(2, Stream.empty))
Stream(1, 2, 3)
Collections have a special method for obtaining a Stream:
(1 to 1000).toStream // > Stream[Int] = Stream(1, ?)
All operations for lists can also be applied to this data structure.
For example,
((1000 to 10000).toStream filter isPrime)(1)
However, :: always creates a list, not a Stream, so #:: is used for streams:
x #:: xs == Stream.cons(x, xs)
The stream implementation is very similar to the list implementation. However, there is one significant difference:
def cons[T](hd: T, tl: => Stream) = new Stream {
def isEmpty = false
def head = hd
def tail = tl
}
The parameter tl uses call-by-name rather than call-by-value. This is exactly why the tail is computed only when necessary.
Lazy Evaluation
However, the implementation proposed above has a drawback that significantly affects performance: if a list element is requested multiple times, the entire list will be recomputed each time.
This can be avoided by saving the computed value on the first call and returning the pre-computed data on subsequent requests.
This technique is called lazy initialization, and in Scala it is done using the keyword lazy:
lazy val x = expression
Thus, Stream can be rewritten as:
def cons[T](hd: T, tl: => Stream) = new Stream {
def isEmpty = false
def head = hd
lazy val tail = tl
}
Infinite Sequences
Using streams, sequences of unlimited size can be created link:
def from(n: Int): Stream[Int] = n #:: from(n + 1)
val natural = from(0)
natural map (_ * 4)
Moreover, if a for-expression is applied to an infinite list, the result will also be lazy
val legals = b.legalNeighbors.toStream
for ((nextBlock, move) <- legals) yield (nextBlock, move :: history)
Example: Sieve of Eratosthenes
To compute prime numbers:
- Start with $i = 2$
- Remove from the result all multiples of $i$
- Move to the next element of the result and repeat
def sieve(s: Stream[Int]): Stream[Int] =
s.head #:: sieve(s.tail filter (_ % s.head | = 0)) | |val primes = sieve(from(2))
(primes take N).toList
Miscellaneous
Tuples and Pairs
Consider merge sort
Algorithm:
- Split the list in half
- Sort the resulting sublists
- Merge them into one sorted list
def msort(xs: List[Int]): List[Int] = {
val n = xs.length / 2
if (n == 0) {
xs
} else {
val (fst, snd) = xs splitAt n
merge(msort(fst), msort(snd))
}
}
def merge(xs: List[Int], ys: List[Int]) = xs match {
case Nil => ys
case x :: xs1 =>
ys match {
case Nil => xs
case y :: ys1 =>
if (x < y) x :: merge(xs1, ys)
else y :: merge(xs, ys1)
}
}
In this example, the splitAt function returns two sublists as a pair.
In Scala, a pair is written as (x1, x2)
val pair = ("answer", 12) // type: (String, Int)
Pairs can be used in pattern matching:
val (label, value) = pair
laber == "answer"
value == 12
A pair is a tuple of two elements, and everything above works for tuples of higher dimensions as well.
Since pairs can be used in pattern matching, the merge function can be rewritten as follows:
def merge(xs: List[Int], ys: List[Int]): List[Int] = (xs, ys) match {
case (Nil, _) => ys
case (_, Nil) => xs
case (x :: xs1, y :: ys1) =>
if (x < y)
x :: merge(xs1, ys)
else
y :: merge(xs, ys1)
}
Implicit Parameters
The msort function only sorts numbers. How can it be made more general?
For example, a comparison function can be passed for comparing two objects
def msort[T](xs: List[T], ys: List[T])(lt: (T, T) => Boolean): List[T] = {
...
def merge[T](xs: List[T], ys: List[T]): List[T] = (xs, ys) match {
...
case (x :: xs1, y :: ys1) =>
if (ls(x, y))
...
}
merge(msort(fst)(lt), msort(snd)(lt))
}
msort(xs)((x, y) => x < y)
msort(xs)((x, y) => x.compareTo(y) < 0)
Scala already has comparison functions that can be used:
import math.Ordering
msort(nums)(Ordering.Int)
msort(fruits)(Ordering.String)
However, this implementation has a problem: the ls parameter must be passed constantly. This can be avoided using implicit parameters
def msort[T](xs: List)(implicit ord: Ordering) = {
...
def merge(xs: List[T], ys: List[T]) = {
...
if (ls(x, y))
...
}
merge(msort(fst), msort(snd))
}
Now the last parameter can be omitted entirely; the compiler will find the correct value of the needed type for the implicitly specified parameter
import math.Ordering
msort(nums)
msort(fruits)
For values to be used implicitly by the compiler, they must satisfy the following rules:
- must be marked with the keyword
implicit - have the corresponding type
- and be visible
In all other cases, an exception will be thrown