Information Retrieval
Information Retrieval is about quickly finding materials in a large collection of unstructured data
- IR is theories, principles and algorithms to find relevant information for a collection of unstructured data - usually text data
Information Retrieval System
IR system:
- A user of an Information Retrieval system has some information need which he wants to satisfy by sending it a query
- The system returns a list of results ranked by relevance
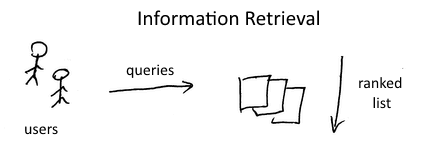
So,
- general goal of IR systems: rank relevant items much higher than non-relevant
- to do it, the items must be scored, and it’s done with a retrieval function
IR Problem
Problem:
- we have a large data collection of unstructured data
- user interacts with the collection by sending a query
- we find some results, but in what order should they be presented?
The ‘‘central problem’’ of IR is ranking elements of the collection according to relevance for a user query
Text IR:
- Most common usecase for IR systems is finding something in textual data
- the ‘'’goal’’’ of textual IR system is to retrieve most relevant documents for the user
Basic formulation:
- Given a collection $C = {d_1, d_2, \ … \ , d_N }$ and a query $q \in Q$
- IR system given $q$ returns a ranked list of ‘‘relevant’’ documents from $C$
- documents are ‘‘relevant’’ when they contain information that the user looks for e.g. they contain the answer to the query
Relevancy
'’Retrieval function’’ is a scoring function that’s used to rank documents
- retrieval function is based on a retrieval model
- Retrieval Model defines the notion of relevance and makes it possible to rank the documents
- the model should be able to represent both objects in the collection and the queries
- for documents the most popular one is Vector Space Model
- but there are other Information Retrieval Models: e.g. Probabilistic Retrieval Model
Given the model we define a retrieval function $s$
- $s: Q \times C \to \mathbb R$
- it takes a query and and a document form $C$ and returns a rank value: some real number
- we can apply $s$ to all documents in $C$ to rank them
Which documents are relevant?
- in the Vector Space Model
- assumption: relevance of a document $d$ w.r.t. to a query $q$ correlated with similarity between query and document:
- So can use some similarity function $\text{similarity}(d, q)$ to find if a document is relevant
- so the retrieval function can be a similarity function, and you’ll just need to sort all documents in $C$ by their similarity to $q$
Retrieval Process
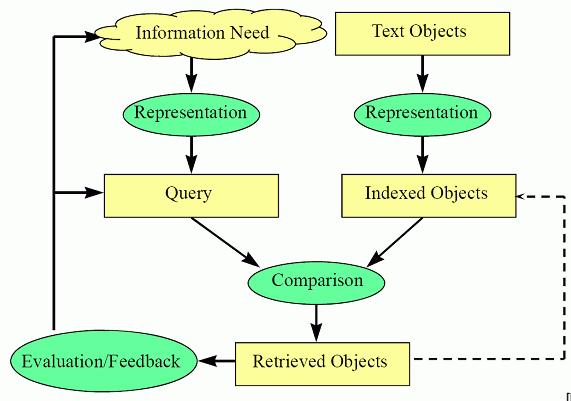
- source: Information Retrieval (UFRT) L01-introduction.pdf
The retrieval consists of several phases:
- offline:
- collection preparation
- parse documents
- build Inverted Index: index the documents so they can be retrieved faster
- online:
- query preparation (parse the query)
- find relevant documents and rand them according to the relevance score
Plus, the ranking may account user’s preferences:
- To make the results better
- To personalize the output
- Also we may want to account for user feedback
Evaluation
How to evaluate an IR system?
- use an IR test collection which consists of:
- documents
- queries
- and know relevance of each query for each document
Given a test collection, the quality of an IR system is evaluated with:
- Precision and Recall
- Precision: % of relevant documents in the result
- Recall: % of retrieved relevant documents
Definitions:
- If $X \subseteq C$ is the output of the IR system and $Y \subseteq C$ is the list of all relevant documents
- then $P = \cfrac
Document Clustering for IR
Ranked list is not the only way of presenting the retrieval results to the user
- the results can also be clustered
- so we want to present internal relationships between documents to IR user when outputting the result
- Scatter/Gather, a variant of K-Means for documents - first popular IR clustering technique, used for clustering web search results
There are two ways to cluster the results:
- search-result clustering (post-retrieval document clustering)
- pre-retrieval document clustering
Pre-retrieval
- Lingo: use Matrix Decomposition techniques to produce low-dimensional basis for the document space
- these base vectors can be interpreted as semantic vectors of the space
- find clustering using SVD or Non-Negative Matrix Factorization
Sources
- Information Retrieval (UFRT)
- Zhai, ChengXiang. “Statistical language models for information retrieval.” 2008.
- http://datascience.stackexchange.com/questions/1106/how-to-build-a-textual-search-engine