Memory Hierarchy
- CPU and its cache
- Main Memory
- Secondary Storage
Important consequence:
Block and Record Addresses
Blocks (and Records) can be in
- the main memory
- their ‘'’address’’’ is the address of the 1st byte of the block (record)
- the secondary storage
- and the ‘'’address’’’ is: device id, cylinder number, etc.
- A record can be identified by an offset within a block
There are several ways to represent an address in the secondary memory
Physical Address
- host, disk id, cylinder id, track, block, offset
Logical (Structured) Address
- arbitrary string of some fixed length
- a ‘‘map table’’ knows how to translate logical address to physical

Logical table and map table give us flexibility
- may move data around as we want
- making sure we maintain same logical address
Point Swizzling
- Initially all pointers have physical address
- but when we load them into memory, we need to ‘‘swizzle’’ (translate) them to main memory address
Arranging Data on Disk
physical algorithms depend on
- how data (relations, records, shemas) is organized on disk
- what data structures are used
Definitions
- a ‘‘data element’’ (a tuple of object) is represented by a ‘‘record’’, which consists of consecutive bytes on some disk block
- '’header’’ is a region that contains some meta information about the record
many machines allow more efficient access for main memory chunks when the data is addressed by a multiplier of 4 or 8
Fixed-Length Records
This is the simplest sort of records
- they consist only of fixed-length fields
a record starts with a fixed-length header, which may store
- a pointer to the schema
- length of the record (to go through records without looking at the schema)
- timestamps - when the record was last modified or read (useful for transactions)
Example
CREATE TABLE MovieStar (
name CHAR(30) PRIMARY KEY,
address VARCHAR(255),
gender CHAR(1),
birthday DATE
);
- name: 30 bytes - allocate 32 (multiplier of 4) to allow faster access
- address: 255 + 1 bytes (255 bytes for text, 1 for the string endmarker)
- gender: either M or F, 4 bytes
- birthday: 10 bytes, allocate 12 bytes

Blocks
- There records are stored in blocks of the disk and moved into the main memory along with the entire block

- we pack as much as possible to the block, and leave the remaining space unused
A ‘‘block header’’ may hold
- which relation this block belongs to
- timestamp that shows time of the last access
- other things
Offset Table
Another way to organize records within a block is to keep an ‘‘offset table’’ in the header

The block is populated with records from the end
- useful when records can be of different length
- in this case don’t know in advance how many records the block will hold
Variable-Length Data Records
Not everything can be represented by fixed-length records:
- data items with varying size
- addresses can be 256 bits, but usually not longer than 50 bits
-
can safe a lot of space - repeated fields - for example in many-to-many relationships we want to store many pointers within one record
- variable-format records
- when schema is not knows in advance (say JSON or XML)
- media streams
- MPEG video or audio
When there are fields whose length can vary we should locate them in such a way that we can find them
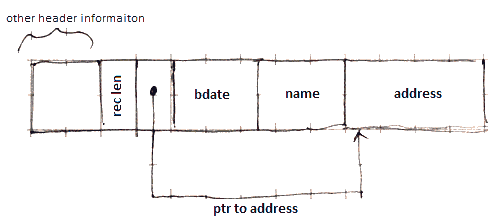
Put Fixed-Length Fields Ahead
- Put all fixed-length fields ahead
- then add to the header:
- length of the whole record
- pointers (offsets) to all variable-length fields
- not needed to include the pointer to the first such field - since there are only fixed-length fields before it, can already calculate the address
To represent a NULL value we just put a null-pointer value to the pointer
Example
Repeating Fields
Say we have a fixed-length field $F$ but it can repeat a number of times
- in this case we can group all occurrences together
- to locate an item we keep 2 values: length $L$ and offset $O$ to the first item
- to get $i$th value we can:
- $O + (i - 1) \cdot L$
Example
- one movie star can have several movies
- we can represent it by pointers to movie records
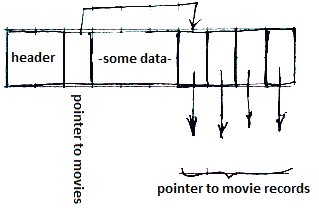
Alternative Approach
Alternatively to #Put Fixed-Length Fields Ahead
- we keep records of fixed length in the block, but
- the variable-length portion of a record - in a separate block
- good for variable-length fields and repeating fields
So in records we keep
- pointers to place where each var-length field begins and
- either how many repetitions there are or
- where the field ends
Example
- address + len, name + len, movies + number of references
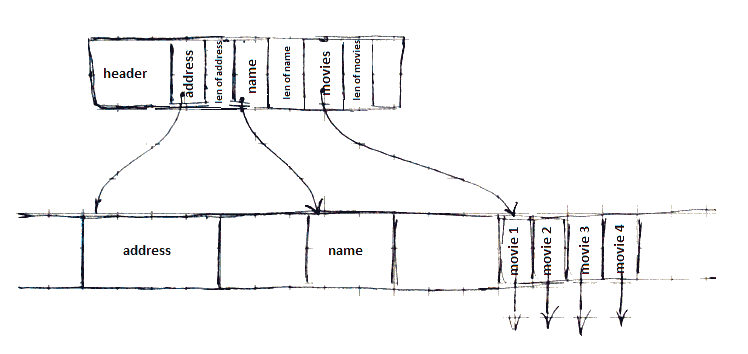
Advantages
- keeping records fixed-sized allows for more efficient serach
- minimizes overhead in block records
- allows records to be moved easier
Disadvantaged
- storing record on another block increases the number of I/O operations (see I/O Model of Computation)
Records Spanning Several Blocks
How to store records that are larger than a block?
- technique for storing such records as called ‘‘spanned records’’
This technique is also useful when records are smaller than a block, but storing them within a block wastes lots of space
- say a record takes 51% of a block
-
then 49% of each block will be wasted (cannot put another record there)
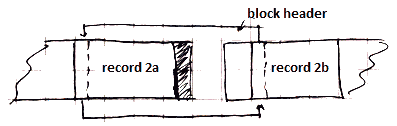
- A portion of a record that appears in one block is called a ‘‘record fragment’’
- A record with 2 or more fragments is called ‘‘spanned’’, otherwise (it lays within one block) - it’s ‘‘unspanned’’
To store a record fragment we need some extra information in the header
- a bit to indicate if it’s a fragment or not
- 2 bits to tell if it’s the first of the last fragment of a record
- if there’s a next or previous fragment we need a pointer to them
Example of a record spanning 2 blocks:
BLOBs
Now let’s consider truly enormous records
- Such objects are binary and large
- BLOBs - binary large objects
Storage of BLOBs
- a BLOB should be stored sequentially, so it may be retrieved efficiently
- it’s also possible to store it in a linked list of blocks
Column Stores
Record Modification
- Insertions, deletions and updates of records often cause problems
- Most severe problems happen when records change their length
Insertion
Suppose we insert a new record into a relation
if there’s no particular order,
- we just find a block with some empty space (or get a new one)
- and put the record there
But if we must keep some order (say we want records be sorted on the primary key):
- first locate the appropriate block
- suppose there’s room to fit the record
- to preserve order we may need to slide down some records to free space at the proper point
- and then we just put the record into that place
- in this case may also need to modify the offset table:
- change pointers for the moved records
- add a pointer to the new one
- be careful with Point Swizzling
- if no room for a records in the block
- need to find space outside of the block
- (2 major approaches discussed below)
Approach 1: Nearby Blocks
Look for room on a nearby block
For example
- block $B_1$ doesn’t have space, but following it $B_2$ has
- so we move the highest records of $B_1$ to $B_2$
- slide the records around on both blocks
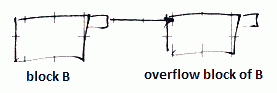
Approach 2: Overflow Blocks
We can create ‘‘an overflow block’’
- each block $B$ has a pointer to a special block where additional records are kept
- by “additional” we mean records that theoretically belong to $B$, but don’t fit in
- these blocks are called ‘‘overflow’’ blocks
-
- in such a way we can link blocks together to have a list of overflow blocks
Deletion
When we delete a record, we may want to reclaim the freed space
If we use an offset table, and can move records around the block,
-
- then we can compact the space
- note the unused space: we can just shift all the remaining records a bit
If we cannot move records,
- we should maintain a list of available space addresses in the header
- to be used afterwards when inserting
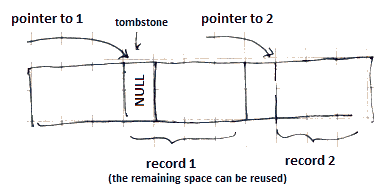
Tombstones
Dangling Pointers
- there might be pointers to occupied records (e.g. see Point Swizzling)
- we don’t want these pointers to dangle or point to wrong records
Usual technique in this case
- to place a ‘‘tombstone’’ in place of the record being deleted
- the tombstone is permanent: it must exist until the DB is reconstructed
Where to put a tombstone depends on the nature of record pointers
- for offset table: could be a NULL-pointer in the offset table
- for map table (see #Logical (Structured) Address): a tombstone could be a NULL-pointer returned from the map table
If we need to replace records by tombstones,
- we should have a bit that indicates whether a record is a tombstone or not
- only this bit (or byte) must remain untouched
- the rest can be reused safely
-
- example
Update
When a fixed-length record is updated, it causes no effect on the storage system
But it’s not the case for variable-length records
- here we have all problems associated with both insertions and deletions
- (except for tombstones - we won’t create them)
If the updated version is longer that the old one
- we’ll need to find more space on the block
- it may involve sliding records or creating overflow blocks
- if portions are stored on another block, we may need to move elements around that block or create a new one
If the new version is shorter, we may want to reclaim the freed space for later use
- same as with #Deletion
Sources
- Database Systems: The Complete Book (2nd edition) by H. Garcia-Molina, J. D. Ullman, and J. Widom
- Database Systems Architecture (ULB)