Contents
[hide]Chi-Squared Test of Independence
This is one of χ2 tests
- one-way table tests - for testing Frequency Tables, Chi-Squared Goodness of Fit Test
- two-way table tests - for testing Contingency Tables, this one
χ2 Test of Independence
This is a Statistical Test to say if two attributes are dependent or not
- this is used only for descriptive attributes
Setup
- sample of size N
- two categorical variables A with n modalities and B with m modalities
- dom(A)={a1,...,an} and dom(B)={b1,...,bm}
- we can represent the counts as a Contingency Table
- at each cell (i,j) we denote the observed count as Oij
- also, for each row i we calculate the "row total" ri=∑mj=1Oij
- and for each column j - "column total" cj=∑ni=1Oij
- Eij are values that we expect to see if A and B are independent
|
|
Test
We want to check if these values are independent, and perform a test for that
- H0: A and B are independent
- HA: A and B are not independent
We conclude that A and B are not independent (i.e. reject H0 if we observe very large differences from the expected values
Expected Counts Calculation
Calculate
- Eij for a cell (i,j) as
- Eij=row j totaltable total⋅column i total
or, in vectorized form,
- [r1 r2 ... rn]×[c1⋮cm]×1N
- with n rows and m columns
X2-statistics Calculation
Statistics
- assuming independence, we would expect that the values in the cells are distributed uniformly with small deviations because of sampling variability
- so we calculate the expected values under H0 and check how far the observed values are from them
- we use the standardized squared difference for that and calculate X2 statistics that under H0 follows χ2 distribution with df=(n−1)⋅(m−1)
X2=∑i∑j(Oij−Eij)2Eij
Apart from checking the p-value, we typically also check the 1−α percentile of χ2 with df=(n−1)⋅(m−1)
Size Matters
In examples we can see if the size increases, H0 rejected
- so it's sensitive to the size
- see also here on the sample size [1]
Cramer's V
Cramer's Coefficient is a Correlation measure for two categorical variables that doesn't depend on the size like this test
Examples
Example: Gender vs City
Consider this dataset
- Dom(X)={x1=female,x2=male} (Gender)
- Dom(Y)={y1=Blois,y2=Tours} (City)
- O12 - # of examples that are x1 (female) and y2 (Tours)
- E12 - # of customers that are x1 (female) times # of customers that y2 (live in Tours) divided by the total # of customers
If X and Y are independent
- ∀i,j:Oij≈Eij should hold
- and X2≈0
Small Data Set
Suppose we have the following data set
- this is our observed values
And let us also build a ideal independent data set
- here we're assuming that all the values are totally independent
- idea: if independent, should have exactly the same # of male and female in Blois,
- and same # of male/female in Tours
|
|
Test
- To compute the value, subtract actual from ideal
- X2=(55−50)250+(45−50)250+(20−25)225+(30−25)225=3
- with df=2, 95th percentile is 5.99, which is bigger than 3
- also, p-value is 0.08 < 0.05
- ⇒ the independence hypothesis H0 is not rejected with confidence of 95% (they're probably independent)
R:
tbl = matrix(data=c(55, 45, 20, 30), nrow=2, ncol=2, byrow=T)
dimnames(tbl) = list(City=c('B', 'T'), Gender=c('M', 'F'))
chi2 = chisq.test(tbl, correct=F)
c(chi2$statistic, chi2$p.value)
Bigger Data Set
Now assume that we have the same dataset
- but everything is multiplied by 10
|
|
Test
- since values grow, the differences between actual and ideal also grow
- and therefore the square of differences also gets bigger
- X2=(550−500)2500(450−500)2500+(200−250)2250+(300−250)2250=30
- with df=2, 95th percentile is 5.99
- it's less than 30
- and p value is ≈10−8
- ⇒ the independence hypothesis is rejected with a confidence of 95%
tbl = matrix(data=c(55, 45, 20, 30) * 10, nrow=2, ncol=2, byrow=T)
dimnames(tbl) = list(City=c('B', 'T'), Gender=c('M', 'F'))
chi2 = chisq.test(tbl, correct=F)
c(chi2$statistic, chi2$p.value)
So we see that the sample size matters
- possible solution is to use Cramer's Coefficient that tells how much two variables correlate
Example: Search Algorithm
Suppose a search engine wants to test new search algorithms
- e.g. sample of 10k queries
- 5k are served with the old algorithm
- 2.5k are served with
test1algorithm - 2.5k are served with
test2algorithm
Test:
- goal to see if there's any difference in the performance
- H0: algorithms perform equally well
- HA: they perform differently
How do we quantify the quality?
- can view it as interaction with the system in the following way
- success: user clicked on at least one of the provided links and didn't try a new search
- failure: user performed a new search
So we record the outcomes
| current | test 1 | test 2 | total | |
|---|---|---|---|---|
| success | 3511 | 1749 | 1818 | 7078 |
| failure | 1489 | 751 | 682 | 2922 |
| 5000 | 2500 | 2500 | 10000 |
The combinations are binned into a two-way table
Expected counts
- Proportion of users who are satisfied with the search is 7078/10000 = 0.7078
- So we expect that 70.78% in 5000 of the current algorithm will also be satisfied
- which gives us expected count of 3539
- i.e. if there is no differences between the groups, 3539 users of the current algorithm group will not perform a new search
| current | test 1 | test 2 | total | |
|---|---|---|---|---|
| success | 3511 (3539) | 1749 (1769.5) | 1818 (1769.5) | 7078 |
| failure | 1489 (1461) | 751 (730.5) | 682 (730.5) | 2922 |
| 5000 | 2500 | 2500 | 10000 |
Now we can compute the X2 test statistics
- X2=(3511−3539)23539+(1489−1461)21461+(1749−1769.5)21769.5+(751−730.5)2730.5+(1818−1769.5)21769.5+(682−730.5)2730.5=6.12
- under H0 it follows χ2 distribution with df=(3−1)⋅(2−1)
- the p value is p=0.047, which is less than α=0.05 so we can reject H0
-
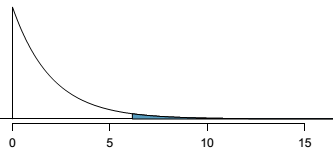
- also, it makes sense to have a look at expected X2 for α=0.05, which is X2exp=5.99, and X2exp<X2
R:
obs = matrix(c(3511, 1749, 1818, 1489, 751, 682), nrow=2, ncol=3, byrow=T)
dimnames(obs) = list(outcome=c('click', 'new search'),
algorithm=c('current', 'test 1', 'test 2'))
tot = sum(obs)
row.tot = rowSums(obs)
col.tot = colSums(obs)
exp = row.tot %*% t(col.tot) / tot
dimnames(exp) = dimnames(obs)
x2 = sum( (obs - exp)^2 / exp )
df = prod(dim(obs) - 1)
pchisq(x2, df=df, lower.tail=F)
qchisq(p=0.95, df=df)
Or we can use chisq.test function
test = chisq.test(obs, correct=F)
test$expected
c('p-value'=test$p.value, test$statistic)