Dense Index
A dense index is a sequence of blocks that can hold only keys and pointers.
- here all records have a record in the index that point to them

Assumptions
- out file (on the right) is ‘‘sequential’’
- i.e. it’s created by sorting all tuples by some attribute, say, primary key
- we can keep 2 records in one block
Benefits
- Can fit more keys in memory at once - and scan there in memory, which is way faster
- can check if record exists without following a pointer (less additional IOs)
Unlike Sparse Index, we cannot stack dense indexes on top of each other
Operations
Lookup
- suppose we want to find a record with $k = 20$
- we locale a record in the index with $k = 20$
- follow the pointer: read the block where it points to

Deletion
Suppose we want to delete $k = 30$
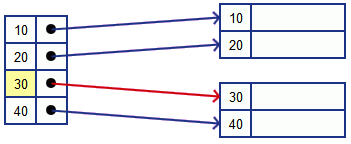
- we follow the pointer for $k = 30$
- then remove the record and the pointer from the index
- we leave a tombstone and reorganize if needed
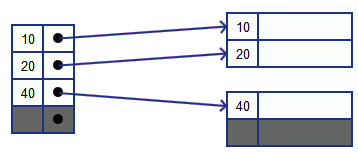
Insertion
- Find the place where the key should belong to
- if there is room in the block, add it there (make sure the order is maintained)
- if not - shift some records out from the block (to a new one or to its neighbor)
- update the index accordingly
Duplicate Keys
Suppose we have duplicate keys in our database. How to build index?
Option 1
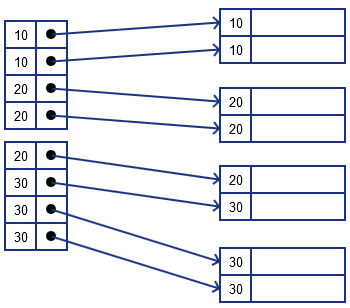
- still like the original dense index: each record has it’s pointer in the index
Option 2
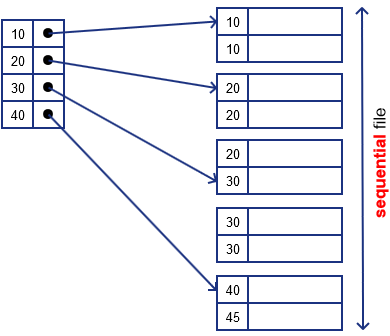
- or we may record only the first occurrence of the key
- assuming the file is sequential, we are sure that the rest will follow
- of course it won’t work if the file is not sequential