Secondary Index
What if we want to support efficient search by some other attribute (not one that is already indexed)
- then the file is not sequentially sorted by this other attribute (it’s sorted on the pk)
- we can make a copy of the entire table - but it’s too expensive
Index structures to do that are Secondary Indexes
Sparse Index?
Doesn’t make sense
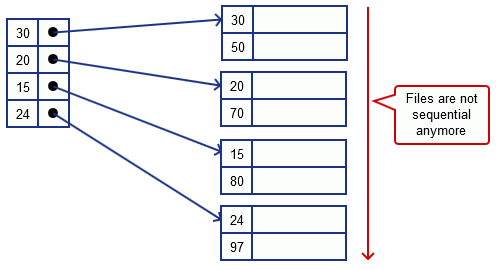
- since the file is sorted by another key
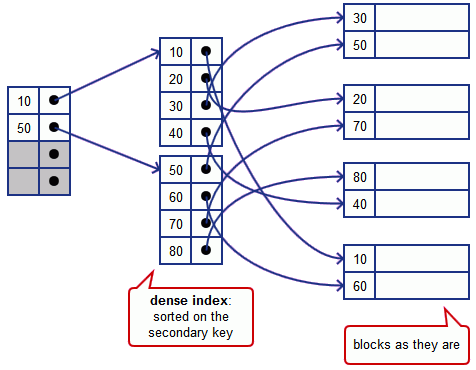
Dense Index?
Idea:
- build a dense index, sort it,
- construct sparse index on it
Duplicates
Just Repeat
Suppose we use Dense Index as our secondary index
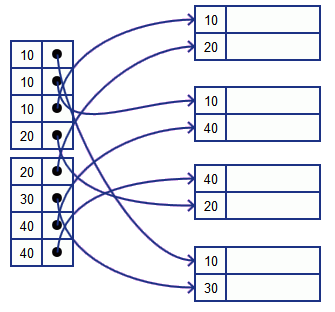
- Same is Option 1 from Dense Index (note that Option 2 will not work here - file is not ordered by this key)
- 10 occurs 3 times - may lead to waste of space
- may look innocent for integers, but often keys are strings
Variable-Length Records
Another way is to use variable-length records
- now need to store the key value only once
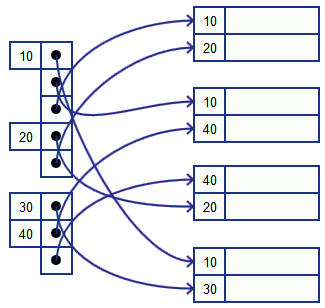
- problem now: need to support variable-length records (which is hard)
Buckets of Pointers
We add one more level of indirection
- we have index on buckets
- buckets are pointers to the actual tuples
So now we have
- Dense Index where each value is stored once
- '’Bucket list’’ where we have multiple occurrences
- pointers to actual values
- should be sequential: i.e. ordered by the key
- Actual blocks
Also saves space| | |Example
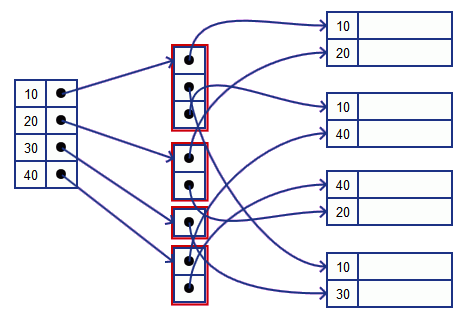
- index pointers point to the first occurrence of 10
- we read buckets down till there’s no 10 anymore
This idea is used in Buckets of Pointers