Hadoop
usually the term ‘‘Hadoop’’ refers to an entire family of products.
So it’s usually a set of products:
- parallel storage (HDFS)
- processing framework (MapReduce implementation)
- Pig/Hive for declarative high-level language support
- HBase as non-relational NoSQL database that runs on HDFS
- Mahout - Data Mining and Machine Learning tool that works on top of Hadoop
Hadoop
- Any combination of them is still referred as Hadoop
- Lots of vendors (like HortonWorks) provide their own distributions of Hadoop
- Even though MapReduce is considered the most important part, it is entirely optional: we may just use HDFS and HBase - and still will consider this combination Hadoop
MapReduce Component
This is a data processing tool on top of HDFS
MapReduce Job Execution
Procession
- each processing job is broken down to pieces
- each piece is given for a map task to execute
- also there are one or more reduce tasks
So it’s performed in two steps
- map phase
- reduce phase
Algorithm
- master picks some idle workers and assigns them a map task
- preparations (before starting the map task)
- input file is loaded to DFS
- it’s partitioned into blocks (typically 64 kb each)
- each block is replicated 3 times to guarantee fault-tolerance
- ’'’map phase’’’
- each block is assigned to a map worker
- it applies the map function to it
- intermediate results are sorted locally
- then it’s stored on local disk of mapper
- it’s partitioned into $R$ reduce tasks
- $R$ is specified beforehand
- partitioning is typically done by ‘'’hash(key) % $R$’’’
- wait until ‘‘all’’ map tasks are completed
- before reduce
- the master assigns reduce task to workers
- the intermediate results are shuffled and assigned to reducers
- each reduces pulls its partition from mapper’s disk
- all map results are already partitioned and stored on mapper disks
- read the input and group it by key
- each record is assigned to only one reduces
- ’'’reduce phase’’’
- now apply the reduce function to each group
- output is stored and replicated 3 times
Hadoop in one picture:
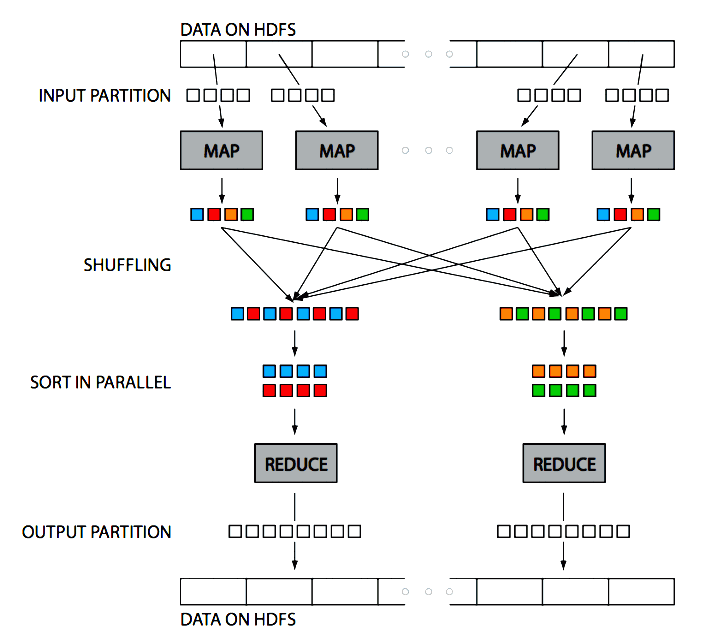
(Figure source: Huy Vo, NYU Poly and [http://escience.washington.edu/get-help-now/what-hadoop])
In short:
- There’s only one Name Node
- the Name Node divides input files into $M$ ‘‘splits’’ (by key)
- then the Name Node assigns ‘‘workers’’ (servers) to perform $M$ map tasks
- while they are computing, it keeps track on their progress
- Workers write their results on local disk dividing it into $R$ regions
- once Map part is done, the Name Node assigns workers to the $R$ reduce tasks
- Reduce workers read the regions from the map workers’ local disks
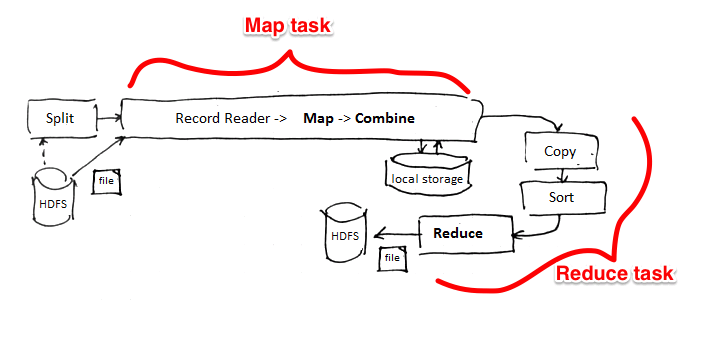
Fault-Tolerance
Achieved because of its Execution Scheme
- detect failures and re-assigns tasks of failed nodes to others in the cluster
- naturally leads to load balancing
Runtime Scheduling Scheme
- For job execution MapReduce component doesn’t build any execution plan beforehand
- It relies on the fault-tolerance scheme that naturally leads to load balancing
- Nodes that have completed are assigned to other data blocks
Result: no communication costs
- MR tasks are done without communication between tasks
Advantages
- MapReduce is simple and expressive
- computing aggregation is easy
- flexible
- no dependency on Data Model or schema
- especially good for unstructured data
- cannot do that in Databases
- can write in any programming language
- no dependency on Data Model or schema
- fault-tolerance
- detect failures and re-assigns tasks of failed nodes to others in the cluster
- high scalability
- even though not in the most efficient way
- cheap
- runs on commodity hardware
- open source
Disadvantages
However it has many disadvantages
No Query Language
No high-level declarative language as SQL
- MapReduce is very low level - need to know programming languages
- programs are expensive to write and to maintain
- programmers that can do that are expensive
- for Data Warehousing: OLAP is not that good in MapReduce
Possible solutions:
Performance
Performance issues:
- no schema, no index, need to parse each input
- may cause performance degradation
- not tuned for multidimensional queries
- possible solutions: HBase, Hive
- because of fault-tolerance and scalability - it’s not always optimized for I/O cost
- all intermediate results are materialized (no Pipelining)
- triple replication
- low latency
- big overhead for small queries (job start time + jvm start time)
Solutions for I/O optimization
- HBase
- Column-Oriented Database that has index structures
- data compression (easier for Column-Oriented Databases)
- Hadoop++ [https://infosys.uni-saarland.de/projects/hadoop.php]
- HAIL (Hadoop Aggressive Indexing Library) as an enhancement for HDFS
- structured file format
- 20x improvement in Hadoop performance
Map and Reduce are Blocking
- a transition from Map phase to Reduce phase cannot be made while Map tasks are still running
- reason for it is that relies on External Merge Sort for grouping intermediate results
- Pipelining is not possible
- latency problems from this blocking processing nature
- causes performance degradation - bad for on-line processing
Solution
- Incremental MapReduce (like in CouchDB [http://eagain.net/articles/incremental-mapreduce/)
Bad High Availability
- single point of failure: the Name Node
- it name node fails, it brings down the entire cluster
- solutions:
- use special hardware for it
- regularly back up
Fixed Data Flow
- Sometimes the abstraction is too simple
- many complex algorithms are hard to express with this paradigm
- Design
- read simple input
- generate simple output
- Again, tools like Hive can help
Other
And finally, it’s very young
Hadoop for Data Warehousing
Links
- http://www.stanford.edu/class/ee380/Abstracts/111116.html - a lecture about Hadoop from Cloudera CTO
See also
Sources
- Lee et al, Parallel Data Processing with MapReduce: A Survey [http://www.cs.arizona.edu/~bkmoon/papers/sigmodrec11.pdf]
- Ordonez et al, Relational versus non-relational database systems for data warehousing [http://www2.cs.uh.edu/~ordonez/w-2010-DOLAP-relnonrel.pdf]
- Paper by Cloudera and Teradata, Awadallah and Graham, Hadoop and the Data Warehouse: When to Use Which. [http://www.teradata.com/white-papers/Hadoop-and-the-Data-Warehouse-When-to-Use-Which/]
- Introduction to Data Science (coursera)