Vector Space Model
Vector space model is a statistical model for representing text information for Information Retrieval, NLP, Text Mining
- Representing documents in VSM is called “vectorizing text”
- contains the following information: how many documents contain a term, and what are important terms each document has
From Text to Vectors: NLP Pipeline
How do we represent a free text in terms of queries?
- to do we need some preprocessing steps, often called “NLP Pipeline”
- the pipeline may include the following:
- Tokenization - most important step, extracts individual words - “tokens”
- Stop Words Removal - removes functional words
- Stemming or Lemmatization - reduces words to some common form
- or other Text Normalization techniques
- building a VSM model is usually one of the lasts steps of the pipeline
- for IR we also usually build an Inverted Index to speed up querying
Bag of Words Assumption
The main assumptions we’re making about text data:
- word order is not important, only word counts
- Bag of Words = unordered list of terms
- good enough for topic similarity
Independence Assumption
We treat all words as independent
- i.e. the basis vector of the term space (see below) is orthogonal
Document-Term Matrix
Document-Term Matrix - representation of a document for text analysis
- each row of the matrix - is a ‘‘document vector’’
- each component of the document vectors is a concept, a key word, or a term, but usually it’s terms
- documents don’t contain many distinct words, so the matrix is sparse
Term Weighting
For each documents words are weighed
Weights can be:
- binary: 1 if term is present and 0 if not
- term frequency (TF): frequency of each word in a document
- sublinear TF: $\log \text{TF}$: sometimes a word is used too often so we want to reduce its influence compared to other less frequently used words
- document frequency: words that are used more in the collections have more weight
- inverse document frequency (IDF): words that are rare across the document collections may be more relevant than frequent words.
- TF-IDF: combination of sublinear TF and IDF
Document-Term vs Term-Document
So texts are represented by feature vectors with frequency of each term in a lexicon
Notation:
- let $\mathcal D = {d_1, \ … \ , d_m }$ be a set of $m$ documents
- and let $V = {w_1, \ … \ , w_n }$ be a set of $n$ words (the vocabulary)
- let $D$ be the matrix
’'’Term-Document Matrix’’’
- if $D$ is $n \times m$ matrix
- rows of $D$ are indexed by terms $w_i$ and columns are indexed by documents $d_j$
- then $D$ is a Term-Document Matrix and $D_{ij}$ is a weight of $w_i$ in document $d_j$
’'’Document-Term Matrix’’’
- if $D$ is $m \times n$ matrix
- rows of $D$ are indexed by terms $w_j$ and columns are indexed by documents $d_i$
- then $D$ is a Document-Term Matrix and $D_{ji}$ is a weight of $w_j$ in document $d_i$
Notes:
- if $D$ is a Term-Document matrix, then $D^T$ is a Document-Term
- in IR literature Term-Document matrices are used more commonly
- in some applications it’s more convenient to use document-term matrix,
- Document-Term matrices are more often used in software packages, e.g. in scikit-learn
- Document-Term are especially nice especially for large scale processing it’s more convenient to operate rows that are documents
Properties of VSM Matrices
Properties of textual data:
- dimensionality is very large, but vectors are very sparse
-
e.g. vocabulary size $ V = 10^5$, but documents may contain only 500 distinct words - or even less - when we consider sentences or tweets
-
- lexicon of document may be large, but words are typically correlated with each other
-
so number of concepts (“principal components” (see PCA)) is $\ll V $ - may want to account for that
-
- number of words across different documents may wary a lot
- so need to normalize
Since data is high dimensional, we may need special pre-processing and representation
Dimensionality Reduction
Usually done via Feature Selection (called “Term Selection”)
- discard infrequent and very frequent terms
not all terms have the same descriptiveness power w.r.t. domain/topic e.g frequent words like “a”, “the”
- we often eliminate such words from the representation of the text
many infrequent words are eliminated as well
- they are called “hapax logomena”: “said only once” and they are usually spelling errors or neologisms that have not yet been lexicalized (i.e. not a part of the vocabulary)
Geometrical View
A geometrical way to express BoW features is the Vector Space Model
- let $D$ be a document-term matrix
’'’TextVSM’’’: Document Vector Space Model - it’s the Row Space of $D$
- each document $d_i$ is $i$th row of the matrix
- dimensions are words and vectors are documents
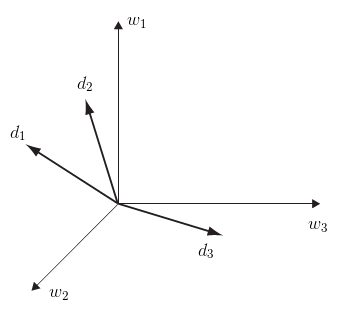
- source: Semantic Domains in Computational Linguistics (book), Fig 3.1
- similarity between two documents: dot product or cosine
’'’TermVSM’’’: Term Vector Space model - it’s the Column Space of $D$
- Can do the same for the terms:
- dimensions are documents and vector are terms
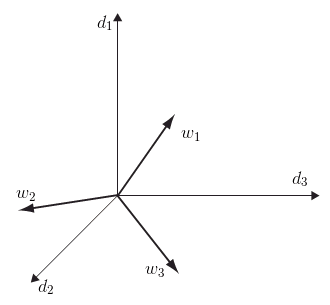
- source: Semantic Domains in Computational Linguistics (book), Fig 3.1
- terms are expressed by documents in which they occur
- similarity between two terms: dot product or cosine
TextVSM and TermVSM appear to be very similar, but in reality they are a bit different
- e.g. Words in the vocabulary of a corpus follow the Zip’s Law: the size of the vocabulary becomes stable when corpus size increases
- it means that the dimensionality of Text VSM is bounded to the number of terms in the language
- not true for the Term VSM: the number of documents can grow forever
- also, the Curse of Dimensionality: paradox: the larger the corpus size is, the worse the similarity estimation in this space becomes
another difference:
- can do feature selection in the Text VSM easily
- but can’t really discard dimensions in the Term VSM: can’t remove one documents and keep others
finally these spaces are disjoint: they don’t hare any common dimensions
- so we can’t measure similarity between a text and a document
Similarities
Common Similarity Measures
Suppose we have two document vectors $d_1, d_2$. Then we can define the following measures of similarity:
- Inner Product: $d_1^T d_2$
-
Cosine Similarity: $\cfrac{d_1^T d_2}{| d_1 | \cdot | d_2 - Dice Coefficient: $\cfrac{d_1^T d_2}{|d_1|^2 + | d_2|^2}$ - Jaccard Coefficient: $\cfrac{d_1^T d_2}{| d_1|^2 + | d_2|^2 - d_1^T d_2}$ - most efficient: normalize $d_1$ and $d_2$ and compute the dot product to get cosine
Document-Document Similarity
With that matrix you can compute the similarity of two documents
- multiply the matrix with its own transpose
- $S = D \cdot D^T$
- The result is a square document - document matrix where each cell represents similarity
- and you have (unnormalized) measure of similarity
- if $D$ is row-normalized, then $S$ contains ‘‘cosine scores’’ between each document
- Cosine Similarity - is a measure of the angle between the two document vectors, normalized by magnitude
- computing $D \, D^T$ may be the first step for Document Clustering
Term-Term Similarity
In some cases term-term similarity can be useful
- e.g. for Term Clustering
- compute $D^T D$ to get pair-wise term similarity
- to get cosine, you need to unit-normalize columns of $D$
- note that if rows of $D$ should not be normalized
Information Retrieval Ranking
In IR a query is also represented in TextVSM
- in such a case the query is called “pseudo-document” $q$
- so ranking is done by computing cosine between the query and all the documents
- it can be done by matrix multiplication: if $q$ and $D$’s rows are unit normalized
- then Matrix-Vector Multiplication $D \, q$ is the cosine score between each doc and the query
- computing $D \, q$ may be computationally expensive when there are many documents in the corpus
- so usually the documents are indexed and we compute the similarity only to whose documents that share at least one word with the query
Advantages and Disadvantages
VSM is the most popular model in IR
Advantages
- Query language is simple
- Ranking - reduces to a dot product
Problems
problems of VSMs:
- Text VSM can’t deal with lexical ambiguity and variability
- e.g.: “he’s affected by AIDS” and “HIV is a virus” don’t have any words in common
- so in the TextVSM the similarity is 0: these vectors are orthogonal even though the concepts are related
- on the other hand, similarity between “the laptop has a virus” and “HIV is a virus” is not 0: due to the ambiguity of “virus”
Term VSM:
- feature sparseness
- if we want to model domain relations, we’re mostly interested in domain-specific words
- such words are quite infrequent compared to non-domain words, so vectors for these words are very sparse, esp in large corpus
- so similarity between domain words would tend to 0
- and the results overall will not be very meaningful and interesting
Solutions:
- Generalized Vector Space Models: Relaxes the Term Independence assumption and uses term co-occurrence information
- Distributed Clusters (Bekkerman et al. Distributional word clusters vs. words for text categorization. 2002)
- Concept-Based Representation (Gonzalo et al. Indexing with WordNet synsets can improve text retrieval. 1998)
- Latent Semantic Analysis
- Domain Spaces
Decomposition of Term-Document Matrix
We can decompose the matrix $D$
- using SVD and we’ll get Latent Semantic Analysis
- LSA can also be done with Non-Negative Matrix Factorization
VSM as an IR/NLP Framework
A VMS is more a (retrieval) framework
VSM has several components:
- term space for representing documents and queries
- document space for representing terms
- similarity/distance measure
Framework:
- The exact vector representation and similarity is not specified
- therefore it’s up to the user to define them
- this flexibility allows to incorporate many advanced indexing techniques and solve problems of VSMs (mentioned earlier) while staying within the framework
Latent Semantic Analysis
For example, consider LSA:
- if we apply SVD to the document-term matrix, we’ll have LSA
- this way we’ll reduce the dimensionality of data and capture some semantic closeness between terms
- by doing this we changed the way documents and terms are represented
- also the similarity is changed slightly
- but overall the framework stays the same
Generalized Vector Space Models
Don’t assume that words are independent
Reference:
- Wong, SK Michael, Wojciech Ziarko, and Patrick CN Wong. “Generalized vector spaces model in information retrieval.” 1985. [http://dl.acm.org/citation.cfm?id=253506])
Sources
- Salton, Gerard, Anita Wong, and Chung-Shu Yang. “A vector space model for automatic indexing.” (1975). [http://cgis.cs.umd.edu/class/fall2009/cmsc828r/PAPERS/VSM_salton-2.pdf]
- Jing, Liping. “Survey of text clustering.” 2008. [http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.112.3476&rep=rep1&type=pdf]
- Semantic Domains in Computational Linguistics (book)
- Information Retrieval (UFRT)
- Zhai, ChengXiang. “Statistical language models for information retrieval.” 2008.